Effective processing of aerial imagery is important for a variety of
socially relevant applications, from conversation monitoring to crisis
preparedness. We've worked directly on applications as well as pursued
improved methodology.
- Multiframe
super-resolution: With a team from Element AI, we have
experimented with approaches to align and fuse low-resolutions
imagery, inspired by the observation that, while high-resolution
data are often expensive, low-resolution views are often plentiful.
- Foundational mapping:
With a team from Intel AI for Social Good, we are working towards
providing locations of bridges, to provide better foundational data
for disaster preparedness planning.
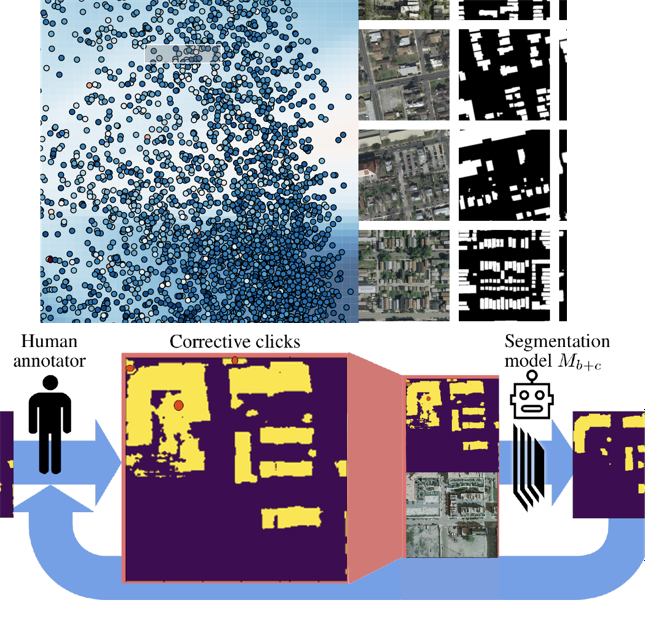
- Interactivity: Mapping
data are often very heterogeneous, so even the best models tend to
require human validation before being used in the field. This
study considers some approaches to interactively refining
preliminary outputs, using weak supervision on prediction masks.
- Interpretability: Remote sensing models hold the potential to
transform a few types of socially relevant monitoring efforts,
from poverty prediction to deforestation tracking. These studies
explore the use of Concept Activation to make these models more
accessible to the domain experts who use them. See these demos (1, 2) and
reports (1, 2).
|
 |